

こんにちは、えびかずきです。
今回はランダムフォレストの使い方について説明していきます。
こんな人におすすめ:
・ランダムフォレストをscikit-learnで実装したい
・どのパラメータを調整すれば良いか教えて欲しい
結論として、scikit-learnのRandomForestClassifierクラス(もしくはRandomForestRegressionクラス)を使えば簡単実装できます。
また、調整すべきパラメータは、n_estimaters(決定木の数),max_features(ランダムに指定する特徴量の数),max_depth(決定木のノード深さ)の3つです。
それでは、順を追って解説していきましょう。
開発環境
Python 3.7.3
scikit-learn 0.24.2
Pandas 1.2.4
seaborn 0.11.1
mglearn 0.1.9
IDE:jupyter Notebook
※mglearnはPythonではじめる機械学習の著者が作成したscikit-learn向けの便利ツールで、学習結果の可視化ができます。
以下のようにpipでインストールできます。
$ pip install mglearnランダムフォレストの使用例
RandomForestClassifierによる実装
まず、データ分類をするサンプル用意します。
今回も例によってscikit-learn.datasetsのirisを使ってみます。
from sklearn.datasets import load_iris
import pandas as pd
# irisのデータをロード
iris = load_iris()
# 使いやすいようにpandasでデータフレーム化
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 今回は2クラス分類をしたいので、3つのクラスの内一つを消去
df['target'] = iris.target
df = df[df['target'] != 0]
df.head()
準備したデータを可視化すると以下のようになります。
import seaborn as sns; sns.set()
sns.scatterplot(data=df, x='petal length (cm)', y='petal width (cm)', hue='target')
import matplotlib.pyplot as plt
plt.xlim(-0, 8)
plt.ylim(-0, 3);
さてそれでは、ランダムフォレストを実装していきましょう。
ランダムフォレストは、以下のようにscikit-learnのRandomForestClassifierクラスで実装できます。
from sklearn.ensemble import RandomForestClassifier
X = df.drop(['sepal length (cm)','sepal width (cm)','target'], axis=1).values
y = df["target"].values
forest = RandomForestClassifier(n_estimators=5, random_state=2)
forest.fit(X, y)
forest.fit(X,y)
forest.score(X,y)
# OUTPUT:
# 0.98訓練データの精度が0.98ということで、きちんと分類ができていますね。
では、結果をmglearnで可視化してみましょう。
import mglearn
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
ax.set_title("Tree {}".format(i))
mglearn.plots.plot_tree_partition(X, y, tree, ax=ax)
mglearn.plots.plot_2d_separator(forest, X, fill=True, ax=axes[-1, -1],
alpha=.4)
axes[-1, -1].set_title("Random Forest")
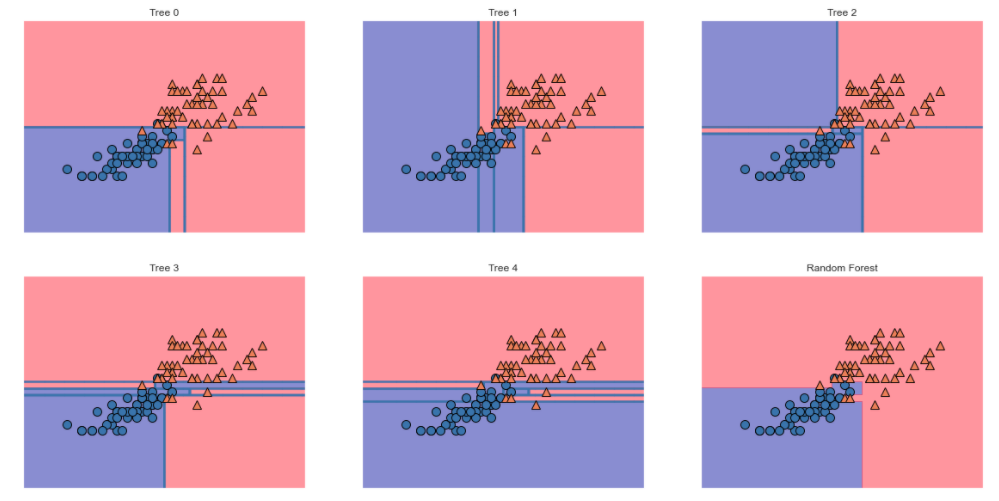
mglearn.discrete_scatter(X[:, 0], X[:, 1], y);結果がこちら。
右下のグラフが最終的にランダムフォレストで多数決をとった結果になります。
他の決定木単体のものと比べると、複雑な空間分割が消えて汎化精度が上がっていそうですね。
パラメータ設定の方法
ランダムフォレストで調整すべきパラメータは、以下の3つです。
n_estimaters:
決定木の数を表します。
要するにこれはバギングで使うブートストラップサンプルの個数に該当します。
多ければ多いほど良いですが、計算コストが高くなるので注意。
ある一定値を超えると分類器としての性能は収束していく。
十分な性能を得るには数百〜数千となることが多い。
デフォルトは少なめの『100』。
max_features:
ランダムに指定する特徴量の数を表します。
デフォルトは特徴量の数(データの次元)の二乗根。
場合によっては変更すると良いこともあるが、あまり調整する数値ではない。
max_depth:
決定木のノード深さの制限値を表します。
デフォルトは『制限なし』で、教師データが一つ残らずクラス分けされるまで空間を分割します。ここもあまり調整する必要はなく、制限を与えずとも十分に大きく決定木の数を取れば良好な性能を達成することが多い。
逆に決定木の数をあまり大きくできない場合、深さに制限を与えることで性能が向上する場合があります。
まとめ
今回はランダムフォレストの使い方について説明しました。
結局のところ、ランダムフォレストはパラメータ調整がほとんど必要ない初心者に優しい分類手法です。
これを言ってはおしまいな感じもしますが、決定木の数をたくさんとって沢山計算をすればそれなりに良い性能を発揮する場合が多いので、とにかくトライしてみましょう。
参考書籍
記事作成にあたって、以下の書籍を参考にさせていただきました。




