

こんにちは、えびかずきです。
今回は決定木の使い方と原理について説明します。
こんな人におすすめ:
・scikit-learnによる機械学習の実装について学びたい
・決定木の原理を詳しく知りたい
結論として、決定木はscikit-learnのDecisionTreeClassifier(もしくはDecisionTreeRegressor)で簡単に実装できます。
一方で原理は単純なので多くの人が感覚的には理解できていると思います。
しかし、どうやって最適な分割条件を決めるかまで詳しく説明できる人は意外と少ないのではないかと思います。
それでは順を追って説明していきましょう!
開発環境
Python 3.7.3
scikit-learn 0.24.2
Pandas 1.2.4
seaborn 0.11.1
graphviz(pip) 0.16
グラフ化:graphviz 2.47.1
IDE:jupyter Notebook
OS:MacOS BigSur 11.2.1
graphvizのインストール
今回は決定木による分類の様子を可視化するためにgraphvizというソフトウェアを使います。
graphviz本体は、MacPCの場合HomeBrewで以下のようにインストールできます。
$ brew install graphvizPythonでグラフを出力するためのライブラリはpipでインストールできます。
$ pip install graphvizscikit-learnによる使用例
今回もirisのサンプルデータを使って使用例を紹介します。
まずirisのデータをロードして、データを可視化します。
from sklearn.datasets import load_iris
iris = load_iris()
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df.loc[df['target'] == 0, 'target'] = "setosa"
df.loc[df['target'] == 1, 'target'] = "versicolor"
df.loc[df['target'] == 2, 'target'] = "virginica"
df.head()import seaborn as sns; sns.set()
sns.scatterplot(data=df, x='petal length (cm)', y='petal width (cm)', hue='target')
import matplotlib.pyplot as plt
plt.xlim(-8, 8)
plt.ylim(-3, 3);
DecisionTreeClassifierによる実装
さてそれでは、決定木によるクラス分類を試してみましょう。
決定木はDecisionTreeClassifierクラスを使って以下のように実装します。
from sklearn.tree import DecisionTreeClassifier
X = iris.data[:, [2, 3]]
y = iris.target
tree = DecisionTreeClassifier()
tree.fit(X,y)
tree.score(X,y)
# OUTPUT:
# 0.9933333333333333訓練データの精度を確認してみると、0.993…としっかり分類ができていますね。
graphvizによる可視化
graphvizというソフトウェアを使って決定木による分類の様子を可視化することができます。
まず、scikit-learnのexport_graphvizを使って「.dot」形式のグラフ化用ファイルを作成します。
今回はクラスの名前を形式的に1,2,3と指定しました。
from sklearn.tree import export_graphviz
export_graphviz(tree, out_file="tree.dot", class_names=["1", "2", "3"],
feature_names=['petal length (cm)','petal width (cm)'], impurity=False, filled=True)そして作成したファイルを使って可視化します。
その結果がこちら↓
色の違いはクラスを表していて、この上の図では橙がクラス1、緑がクラス2、紫がクラス3を表しています。
色が濃いほど誤り率が低い状態を表しています。
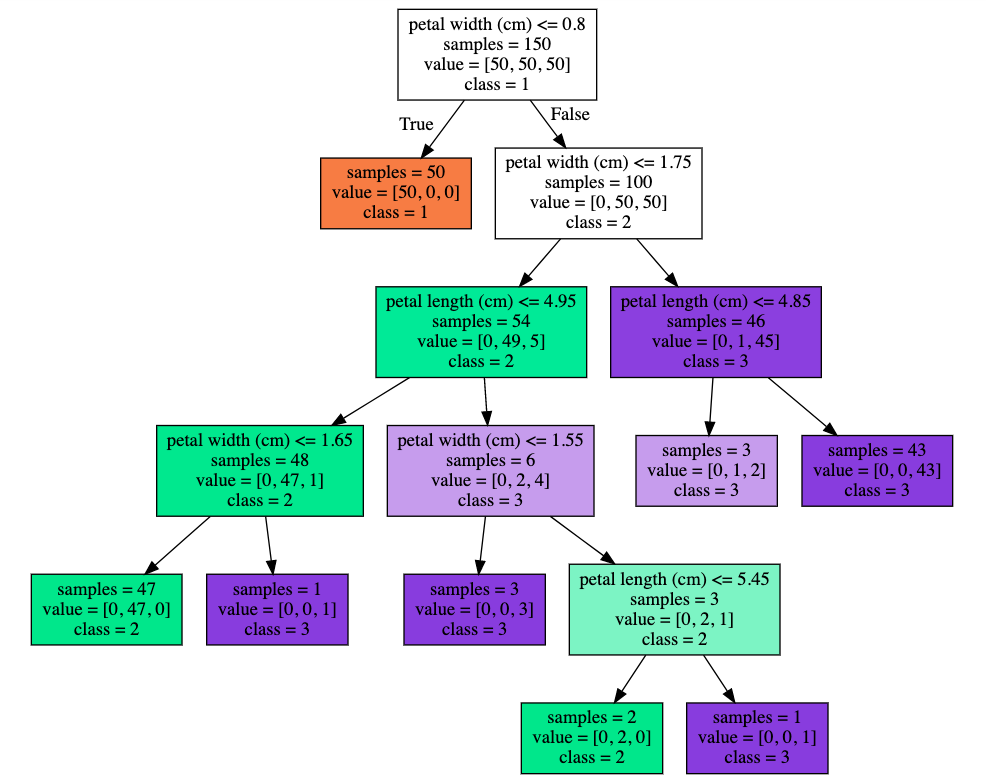
そして、分類結果をプロット図に書き加えたものがこちら↓
単純な3クラスの分類にもかかわらず、分割領域が多めで過学習気味ですね。
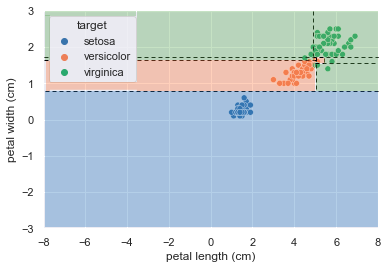
ではどのように過学習を回避すれば良いでしょうか?
枝刈り
DecisionTreeClassifierでは過学習を回避するために、『max_depth』,『max_leaf_node』,『min_sample_leaf』の3つのパラメータ指定ができます。
決定木ではこれを枝刈りと呼ぶことがあります。
3つ全て使うというよりは、いずれか1つのパラメータを指定して、過学習を抑えるのが一般的です。
ここでは『max_depth』を3に指定して、分類をやり直してみましょう。
from sklearn.tree import DecisionTreeClassifier
X = iris.data[:, [2, 3]]
y = iris.target
tree = DecisionTreeClassifier(max_depth=3)
tree.fit(X,y)
tree.score(X,y)
# OUTPUT:
# 0.9733333#graphvizによる視覚化
export_graphviz(tree, out_file="tree.dot2", class_names=["1", "2", "3"],
feature_names=['petal length (cm)','petal width (cm)'], impurity=False, filled=True)
with open("tree.dot2") as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))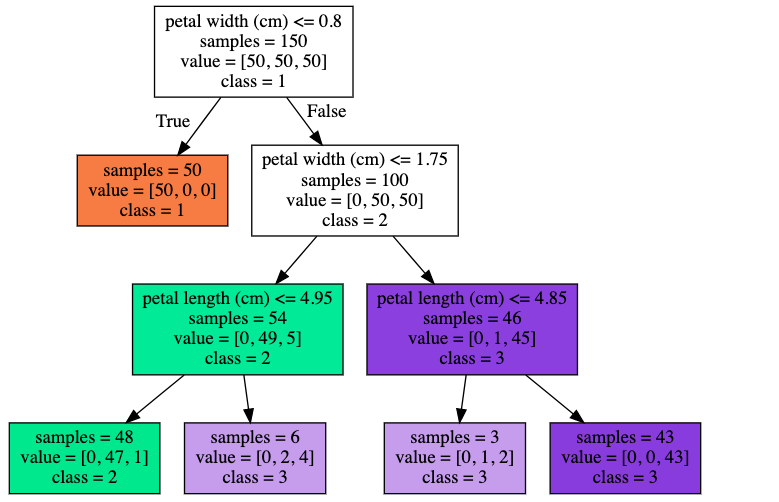
訓練データのスコアは下がりましたが、
下図のとおり、割とマシな分類結果になりました。
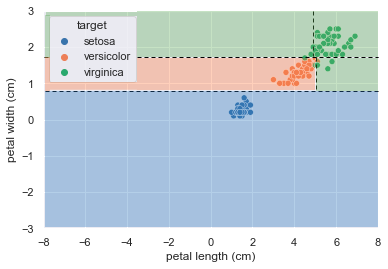
DecisionTreeRegressorによる実装
決定木はDecisionTreeRegressorというクラスを使うことでも実装できます。
使いかたはDecisionTreeClassifierとほとんど同じで以下のように記述します。
from sklearn.tree import DecisionTreeRegressor
X = iris.data[:, [2, 3]]
y = iris.target
tree = DecisionTreeRegressor(max_depth=3)
tree.fit(X,y)
tree.score(X,y)
# OUTPUT:
# 0.9702083333333333決定木の原理
決定木の原理は、一般的に訓練データの特徴空間の分割を繰り返して、空間の領域をクラス別にわけるという仕組みになっています。
これは特に分割統治法と呼ばれています。
これは感覚的には理解しやすいですが、ではどうやって2分割をしていくのでしょうか?
その方法には、確率論的な考え方が必要です。
いくつかの方法があるのですが、ここでは決定木の中でも主流のCARTという方法論について説明していきます。
CARTは空間の”2”分割を繰り返すというところに特徴のある手法です。
そして、空間を2分割するために不純度という指標を使います。
不純度を以下の式で表されるジニ係数で記述します。
\(\displaystyle I(t)=\sum_{i=1}^K \sum_{j\neq i}P(C_i|t)P(C_j|t)\)
これは確率論的な誤り率を示しています。
そこでデータの特徴空間を2分割する前後での変化が最大になるように、すなわち誤り率が最も小さくなるように分割するポイントを選びます。
あとは、これをどんどん繰り返して、空間を分割していけば良いというわけです。
まとめ
今回は決定木の使い方と原理について説明しました。
scikit-learnによる実装は例によって、極めて簡単でしたね。
実際のところ決定木は過学習しやすく精度が出にくい手法なので、それ単体で使うことは滅多にないです。
しかしこれを応用したランダムフォレストなどを使用する場合には、基礎知識として当然決定木を知っておく必要があります。
基礎を固めることこそが高度な理論を理解するための近道なので、じっくり学習を進めていきましょう。
参考書籍
記事作成にあたって、以下の書籍が参考になりました。




