

2019/12/10 プログラム誤植を修正
・#1文字画像の認識(25行目):num_dim→8*16
・#文字列画像の認識(29行目):num_dim→8*16
2021/1/4 プログラム修正
・忖度検定2級挑戦中様ご指摘の内容
こんにちは、えびかずきです。
今回はOCR(光学文字認識)プログラムの自作方法についてまとめました!
こんな人におすすめ:
・ディープラーニングによるOCRプログラムの仕組みを勉強したい。
・実際にPythonのプログラムを走らせてみたい。
こんな人にはおすすめでない:
・TensorFlowでAI開発したい
TensorFlowによる開発は他の記事で紹介していますので、そちらをご参照ください。
ディープラーニングで画風変換を実装する方法【Tensorflow】
Tensorflowで転移学習をする方法【画像分類/VGG16】
学習済みディープラーニングモデルを使って画像分類する方法【TensorFlow/VGG16】
Kerasで学習済みディープラーニングモデルを保存・読込みする方法【Tensorflow】
OCRをPythonで自作する方法
ここでご紹介するのは、ニューラルネットを使った機械学習を使って手書きのアルファベット画像を文字として認識させるプログラムになります。
ご自身の開発環境へコードをコピペして試してみてください。
開発環境
- 使用する言語:Python3.7.3
- 使用するライブラリ:neurolab,numpy,PIL
※これらのライブラリは事前にインストールしておいてください
neurolabがニューラルネットワークを使用するためのライブラリになります。
今回の開発に欠かせないライブラリです。
下のようにpipでインストール可能です。
% pip install neurolab
% pip install numpy
% pip install pillow・IDE:Jupyter notebook
Jupyter notebookは下のようにpipでインストールして、
% pip install jupyter下のコマンドで開くことができます。
% jupyter notebook使用する学習素材
機械学習のプログラムを実行する上で適切な学習素材が必要となります。
本来は自分で素材を準備して使用するのが良いですが、今回はネット上に公開されている機械学習向けの素材を使用させていただきます。
ここでは、Stanford Artificial Intelligence Laboratoryという組織が公開している、小文字アルファベットの手書きデータ集を学習素材として使用します。
素材は”.data”形式のファイルとなっていて、「letter.data」というファイルに全データが入っています。
これをダウンロードして、作成するpythonプログラムと同じフォルダへ保存しておいてください。
このファイルの中身を画像化してみると下図の様になっています。
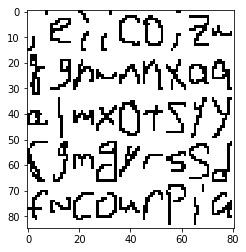
確かに手書き文字の素材になっていて、OCR向けの学習素材としては最適だと思われます。
ちなみに上で画像化して示したアルファベットは「letter.data」のごくごく一部です。
全部でアルファベットは52,152個もあり、とてつもないデータ量です。(これを集めてデータ化するのは大変だったことでしょう。)
ニューラルネットの構成
プログラムを書く前に、まずどのようなニューラルネット構成を組むかを決める必要があります。
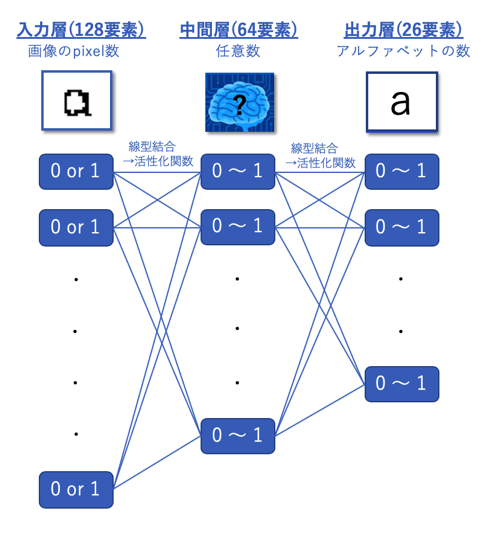
今回は下図の様な入力層、中間層、出力層の三層からなる構成でプログラムを組んでOCRを作成することとします。
※ちなみに、中間層(隠れ層と言う場合もある)が複数あるニューラルネット構成の機械学習を「ディープラーニング」と言います。最近よく耳にしますよね。
OCRプログラム
開発環境と学習素材のダウンロードが出来たら、OCRプログラムの作成を進めましょう。
このプログラムでやろうとしていることは、「解答付きの学習素材をインプットとしてニューラルネットワークに入れて訓練させ、ネットワークを形成するパラメータを最適化する」ということになります。
かなり難易度の高そうな内容に思えますが、
今回は『neurolab』というライブラリを使って、ニューラルネットのプログラムを簡潔に記述していきます。
コードの構成としては、
- ①ライブラリのインポート
- ②変数定義
- ③学習素材の読み込み
- ④データ形式の変換
- ⑤ニューラルネットを生成
- ⑥学習の実施
という流れになります(大部分はデータの読み込みとその加工です)。
これを実行するコードが下になります。
#ocrプログラム
#①ライブラリのインポート
import numpy as np
import neurolab as nl
#②変数定義(use_n:読み込むデータ数 train_n:学習に使用するデータ数)
ans_labels="abcdefghijklmnopqrstuvwxyz"
use_n = 50000
train_n = int(0.9*use_n)
pixel_n = 8*16
ans_n = len(ans_labels)
data = []
labels = []
#③学習素材の読み込み
with open('letter.data', 'r') as f:
for line in f.readlines():
list_vals = line.split('\t')
#正解ラベル(出力データ)
label = np.zeros((ans_n, 1))
label[ans_labels.index(list_vals[1])] = 1
labels.append(label)
#手書きデータ(入力データ)
char = np.array([float(x) for x in list_vals[6:-1]])
data.append(char)
if len(data) >= use_n:
break
#④データ形式の変換(labelsとdataをリスト→配列)
labels = np.array(labels).reshape(-1, ans_n)
data = np.array(data).reshape(-1, pixel_n)
#⑤ニューラルネットを生成(域値:0~1,入力層(128),中間層(64),出力層(26))
nn = nl.net.newff([[0, 1]] * pixel_n, [64, ans_n])
#学習方法としてRpropを指定
nn.trainf = nl.train.train_rprop
#⑥学習の実施
error_progress = nn.train(data[:train_n,:], labels[:train_n,:],
epochs=10000, show=10, goal=5000)コード内容&実行のポイント
②:
読み込むデータ数より学習に使用するデータ数を少なめにしているのは、
後でテストを実施して文字認識率を確かめるのに使うデータを残しておくためです。
③:
letter.dataの中身は、2列目が正解ラベルデータ、7列目以降が手書きデータとなっているので、ここで必要な部分のみを抜き出してやります。
④:
読み込んだデータは③の時点でリストですが、これを数値的に取り扱いやすい様にnumpyの行列ライブラリで配列に変換してやります。
⑤:
「ニューラルネットの構成」のところで示した図に対応するニューラルネットワークをここで組んでいます。
neurolabライブラリを使えば、上コードの通りたったの一行で記述できてしまいます。
訓練の方法としては、勾配法による最適化アルゴリズムの一つである「Rprop」を指定しています。
⑥:
epochは訓練の上限回数、showは結果の表示ステップ、goalは訓練終了のエラー閾値を示しています。
OCRの性能はこのgoalの値によって決まってくるため、この設定値が重要です。一概にどの程度の数値を設定すれば良いなどと言うことはできず、ニューラルネットの構成や取り扱う数値範囲(今回は0~1)、そしてプログラムの用途によって最適な設定値は変わってくるので、
ここは試行錯誤しながら設定する必要があります。
goalに設定した数値に到達しない場合でも、epochsに設定した値まで訓練回数が到達すると、
「The Maximum number of train epochs is reached」
と表示されてプログラムは終了します。
※上コードで設定した条件で実行すると計算に丸一日くらいかかるので、最初はepochsの値を10とか100とか小さい値で試してみることをおすすめします。
文字認識率の測定
訓練を終えたニューラルネットを使って文字認識の正答率を測定してみます。
読み込んだ学習素材のデータの内、訓練として使用したデータを除く残りの10%のデータをここで使います。
下のコードの様に、.sim()メソッドを使って、データをシミュレートさせてみます。
#学習素材でテスト
predicted = nn.sim(data[train_n:, :])
correct = 0
test_n = int(use_n-train_n)
for i in range(test_n):
if ans_labels[np.argmax(labels[train_n+i])]==ans_labels[np.argmax(predicted[i])]:
correct+=1
print('正答率=',100*correct/test_n,'%')このコードのアウトプットとして、79%という数値が得られました!
つまり、約8割程度が文字認識として一致するOCRになっていることがわかりました。
性能テスト
1文字画像の認識
自作OCRが完成したので、
実際に一文字の手書き画像を準備して性能テストをしてみます。
今回はMacのPaintアプリを使ってテスト画像を作成します(Windowsでもペイントソフトで作成可能)。

訓練した学習素材と同じ、8×16pixelにサイズを指定して、画像を編集します。
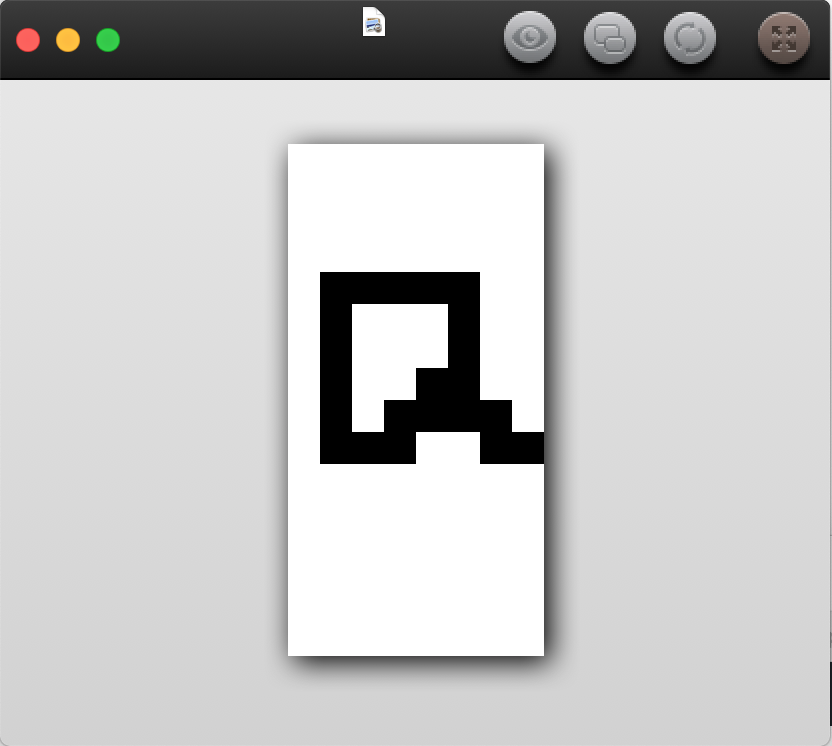
”a”の手書き画像として、下の様な”a.png”テストファイルを作成しました。
これを、以下のコードのインプットとして使用し、OCR性能をテストします。
#1文字画像の認識
from PIL import Image
# 手書き画像の読み込みとimageオブジェクトの作成
img = Image.open('a.png')
width, height = img.size
img2 = Image.new('RGB', (width, height))
# getpixel((x,y))で左からx番目,上からy番目のピクセルの色を取得し、img_pixelsに追加する
img_pixels = []
for y in range(height):
for x in range(width):
img_pixels.append(img.getpixel((x,y)))
# データの規格化
img_pixels_norm = []
for i in range(8*16):
p = img_pixels[i][0]
if p == 0:
img_pixels_norm.append(1.)
else:
img_pixels_norm.append(0.)
img_pixels_norm = np.array( img_pixels_norm).reshape(-1,8*16)
#結果表示
predicted = nn.sim( img_pixels_norm)
print('結果:', ans_labels[np.argmax(predicted)]) 得られたアウトプットは、
結果:a
となりました。無事文字認識に成功しています。
文字列画像の認識
続いての性能テストとして、文字列の認識が出来るかをテストします。
一文字の”a”の時と同じ様にpaintアプリ下の手書き画像”ebiworks”を作成しました。
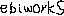
#文字列画像の認識
from PIL import Image
import numpy as np
# 手書き画像の読み込みとimageオブジェクトの作成
img = Image.open('ebiworks.png')
width, height = img.size
img2 = Image.new('RGB', (width, height))
#getpixel((x,y))で左からx番目,上からy番目のピクセルの色を取得し、img_pixelsに追加する
img_pixels = []
for i in range(8):
for y in range(16):
for x in range(8):
img_pixels.append(img.getpixel((x+8*i,y)))
#データの規格化
img_pixels_test = []
for j in range(8):
img_pixels_norm = []
for i in range(8*16):
p = img_pixels[i+j*8*16][0]
if p == 0:
img_pixels_norm.append(1.)
else:
img_pixels_norm.append(0.)
img_pixels_norm = np.array( img_pixels_norm).reshape(-1,8*16)
img_pixels_test.append(img_pixels_norm)
#テスト
result=[]
for i in range(8):
predicted = nn.sim(img_pixels_test[i])
result.append(ans_labels[np.argmax(predicted)])
result_str = ''.join(result)
print('結果:',result_str)これを自作OCRへインプットしてテストします。
このテストコードのアウトプットとして、
結果:ebiwoiks
が得られました。
残念ながら一つだけ間違った結果となってしまいました。
人間の目から見れば、手書き画像の6文字目は明らかに”r”なのですが、今回作成したOCRには”i”に見えてしまったのでしょう。
まとめ
今回は、neurorabライブラリを使うことによって簡単にOCRプログラムを作成する方法を紹介しました。
確かにプログラムは簡単に書けるのですが、機械学習を実用レベルで使用するには、ライブラリの動作原理や、指定パラメータの最適設定が必要になってきます。私自身も機械学習に関しては最近勉強を始めたばかりで実用レベルには至っていないので、さらなる学習が必要だと感じています。
とは言え、やはりまずは自分の手で試してみることが大事です。実際に自分でプログラムを動かしてみると、おのずと何を勉強すべきかが見えてくると思いますので、皆さんも今回の自作OCRを試してみてはいかがでしょうか?





