

こんにちは、えびかずきです!
今回は畳み込みニューラルネット (CNN)の仕組みと、
それを使った画像識別の実装について説明していきます。
CNNの仕組み
CNN(Convolutional Neural Network)はその名のとおり、
畳み込みを実施するニューラルネットワークで、特に画像識別の分野でよく使われます。
では順を追って説明していきましょう!
画像認識におけるNNの問題点
前回までに学んだ単純なNN(ニューラルネットワーク)で画像認識をおこなうと、
画像としてのパターンを完全に無視したピクセル単位の情報伝達になってしまい効率が悪いという問題があります。
それを改善して、画像としてのパターンを保持して情報を伝達するのがCNNです。
下にCNNのレイヤ積層の例を示しました。
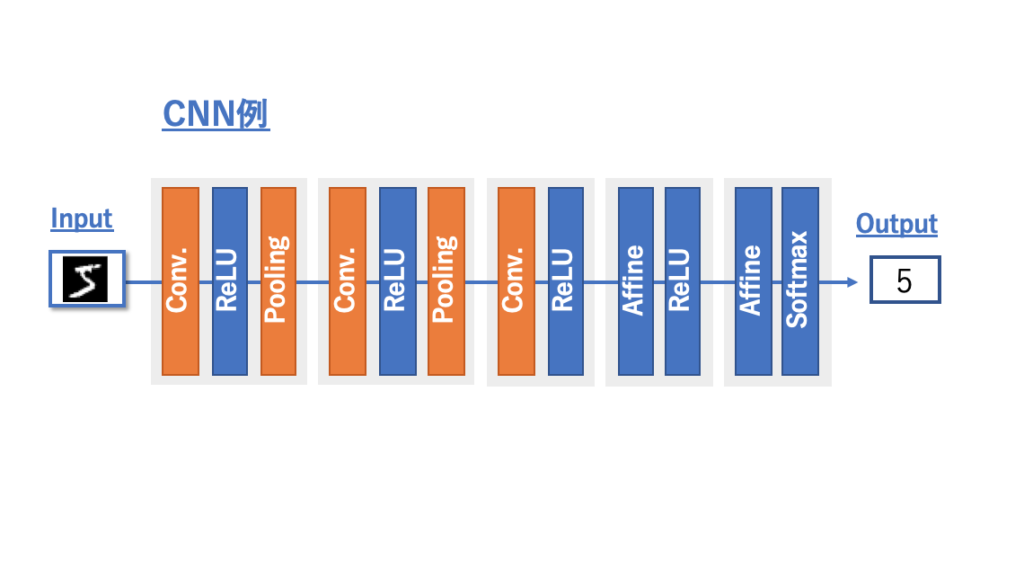
これまでのニューラルネットワークとの違いは、
Convolution(畳み込み)レイヤとPooling(プーリング)レイヤを含んでいることです。
それではそれそれのレイヤで何がおこなわれているのかを見ていきましょう!
Convolution(畳み込み)とは
畳み込みとは、入力データにフィルターを適用して、特徴マップと呼ばれる出力を生成する演算です。
下の例をみてください。
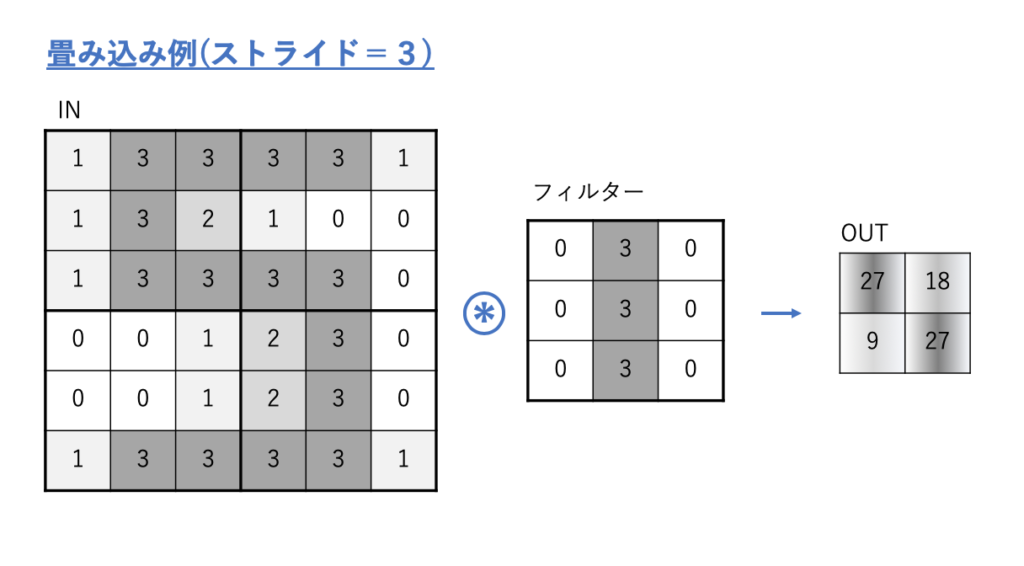
入力データとして「5」を示すような、6×6ピクセルのグレースケール画像があるとします。
ここに上のようなフィルタをストライド=3で適用すると、出力として右上のような2×2の特徴マップが生成されます。
上の例でどんな演算をしているかというと、フィルターを入力データに重ねて、
それぞれのマスの数字の掛け算を足し合わせるという演算をしています。
これは積和演算などと呼ばれています。
フィルターを入力データの左上の角から重ね合わせて、
その積和演算結果を特徴マップの右上の数値として出力し、
その後設定したストライド(3)の分だけ右側にずらして同じ演算を実施します。
この入力画像とフィルタの積和演算を入力画像全体に対して実行して、
得られた出力が畳み込みを実施した特徴マップとなり、
次にレイヤ(だいたい活性化関数のレイヤ)へ受け渡します。
上の例ではストライド=3の例でしたが、たとえばストライド=1の場合は下のようになります。
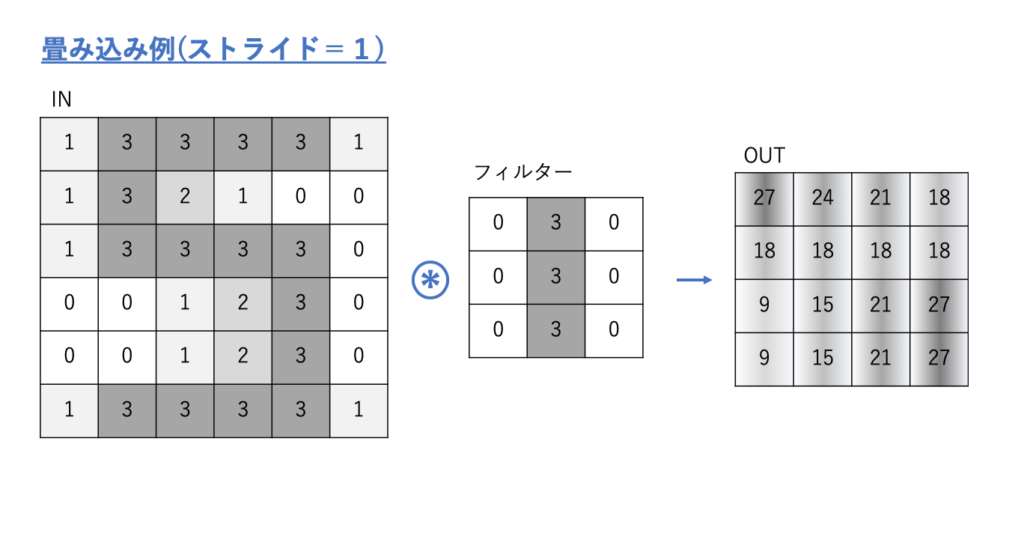
すでにお気づきのとおり、
ストライドの数によって出力の特徴マップのサイズは変化し、その設定値は任意です。
そしてフィルターのサイズによっても特徴マップのサイズは変わり、フィルターのサイズも任意です。
この畳み込みという演算は、画像の局所的なパターンを認識する役割があります。
上の例では、フィルターが真ん中に黒い線の入った縦棒のような画像になっていますが、
これにより生成した特徴マップの数値は、入力画像のそれぞれの領域の「縦棒っぽさ」を示しています。
例のような「5」を示す画像を入力とした場合、
結果の特徴マップは5の縦棒がある右上付近と左下付近の領域の数値が大きくなっています。
ここで使ったフィルターが、これまでのニューロンをつなぎ合わせていた重みに対応しており、CNNでの最適化の対象となります。
つまりCNNでは最適化するフィルターをたくさん準備して、訓練データでモデルを学習させることで効率よく画像認識を行えるというわけです。
Pooling(プーリング)
もう一つの新しいレイヤはプーリングです。
これは畳み込み→活性関数→という順番で流れてきた特徴マップを圧縮する役割があります。
下の例をみてください。
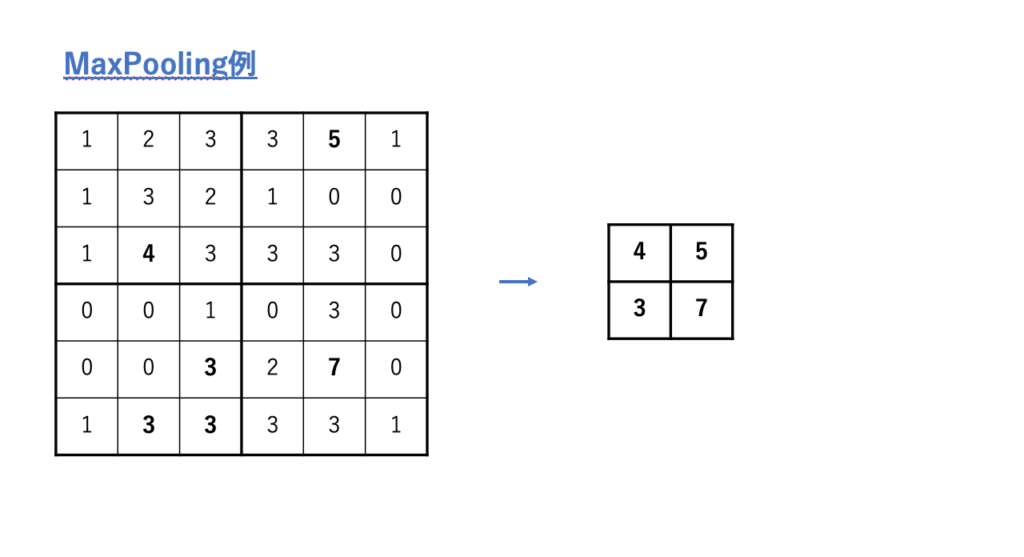
ここではMaxプーリングの例をしめしました。
Maxプーリングとは、入力の特徴マップを一定の領域で区切って(上では3×3ごと)、
その中の最大値のみを抽出して新しい特徴マップとして出力する手順です。
ここでのマスの区切り方は任意です。
あまり広くし過ぎると画像の特徴を失ってしまいますし、せまくし過ぎると情報がうまく圧縮できません。
プーリングという手順は、情報量が圧縮できることに加えて、
情報が「ならされる」という特徴もあります。
プーリング層に入力される特徴マップの微細な平面的特徴が異なっていたとしても、
プーリングによって区切った領域ごとに数値がならさせていきます。
(この良し悪しは場合によりますが)
Maxプーリング以外にも、平均値をとるAverageプーリングなどもあります。
開発環境
OS:macOS Catalina ver10.15.2
使用した外部ライブラリ:
numpy1.18.1
matplotlib3.0.3
エディタ:jupyter notebook
ソースコード
github/ebikazuki/deeplearning
本記事では、「#9」のフォルダを使用します。
畳み込みレイヤの実装
それでは畳み込みレイヤを実装してみましょう。
下にクラスとして定義した畳み込みレイヤのコード例を示しました。
中身の説明は、コード内に記入したコメントを参考にしてください。
class Convolution:
#引数として重み(フィルター)W,バイアスb,ストライドstride,バディングpadを設定
#パディングとは特徴マップの縁を0で埋める処理
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
# 中間データ(backward時に使用)
self.x = None
self.col = None
self.col_W = None
# 重み・バイアスパラメータの勾配
self.dW = None
self.db = None
#順方向の演算を定義
def forward(self, x):
#FN:フィルタの枚数,C:チャンネル数,FH:フィルタ高さ,FW:フィルタ幅
FN, C, FH, FW = self.W.shape
#N:特徴マップの枚数,C:チャンネル数,H:特徴マップ高さ,W:特徴マップ幅
N, C, H, W = x.shape
#パディング
out_h = 1 + int((H + 2*self.pad - FH) / self.stride)
out_w = 1 + int((W + 2*self.pad - FW) / self.stride)
#チャンネルを含む3次元データを2次元データに成形
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T
#畳み込み演算
out = np.dot(col, col_W) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
self.x = x
self.col = col
self.col_W = col_W
return out
#逆方向の演算(逆伝播)を定義
def backward(self, dout):
FN, C, FH, FW = self.W.shape
dout = dout.transpose(0,2,3,1).reshape(-1, FN)
self.db = np.sum(dout, axis=0)
self.dW = np.dot(self.col.T, dout)
self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
dcol = np.dot(dout, self.col_W.T)
dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
return dxプーリングレイヤの実装
続いてプーリングレイヤを実装してみましょう。
下にクラスとして定義したプーリングレイヤのコード例を示しました。
中身の説明は、コード内に記入したコメントを参考にしてください。
class Pooling:
#引数としてプール高さpool_h,プール幅pool_w,ストライド,パディングを指定
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
self.x = None
self.arg_max = None
#順方向の演算を定義
def forward(self, x):
#N:特徴マップの枚数,C:チャンネル数,H:特徴マップ高さ,W:特徴マップ幅
N, C, H, W = x.shape
#pooling後のサイズ計算
out_h = int(1 + (H - self.pool_h) / self.stride)
out_w = int(1 + (W - self.pool_w) / self.stride)
#チャンネルを含む3次元データを2次元データに成形
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h*self.pool_w)
#Max-pooling処理の実行
arg_max = np.argmax(col, axis=1)
out = np.max(col, axis=1)
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
self.x = x
self.arg_max = arg_max
return out
#逆方向の演算(逆伝播)を定義
def backward(self, dout):
dout = dout.transpose(0, 2, 3, 1)
pool_size = self.pool_h * self.pool_w
dmax = np.zeros((dout.size, pool_size))
dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()
dmax = dmax.reshape(dout.shape + (pool_size,))
dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)
dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)
return dxCNNの実装
上で定義した畳み込みレイヤとプーリングレイヤを使ってCNNを試してみましょう!
ここでは、Githubに保存した「#9」フォルダ内の「deeplearning#9.ipynb」を使います。
コードの中身の説明は割愛しますが、
これまでのようにレイヤを重ねてニューラルネットのモデルを作り、
訓練データを入れて学習を進めるというやり方になります。
今回も例によってMNISTの手書き数字画像を使うことにします。
学習モデル:
・モデル構造:Conv-ReLU-Pool-Affine-ReLU-Affine-Softmax
・Convフィルタ数:30
・訓練データ:60,000(MNIST)
・エポック:20
・最適化:Adam
・テストデータ:10,000(MNIST)
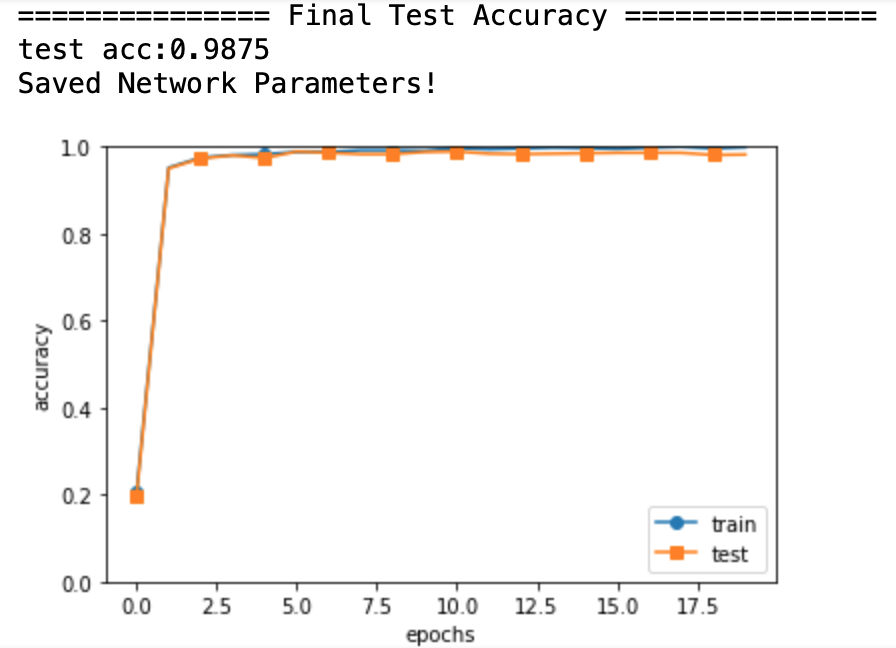
結果として、
テストデータの精度は約99%というかなり高精度の結果を得ることができました。
CNNでモデルを作ったことで、画像としての特徴を保持したままネットワーク内でうまく情報伝達を実施でき、高性能のモデルを作ることができました。
下は、訓練前と訓練後のフィルタを可視化したものです。
訓練前は画像的な特徴のないバラバラな構造になっていますが、
訓練後は画像としての特徴が抽出されそうな画像的パターンを示していることがわかりますね。


学習済みモデル(VGG16)の活用
上のようにCNNモデルを作り訓練データで学習すれば、画像認識ができますが、
目的に合わせて自分で学習モデルを作るには、たいてい大量の学習データが必要になるので、なかなか実践で使うのは難しいのが現状です。
そういった問題を解決する方法として、学習済みのモデルを応用することで画像分類をおこなう方法があります。
VGG16という学習済みモデルを使った画像認識の方法を紹介した記事があるので、やり方はそちらを参考にしてください。
さらなる応用として、
VGG16をそのまま使わず、用途に合わせてモデルを修正して使う「転移学習」についても過去記事がありますので、やってみたい方は参考にしてください。
まとめ
今回は、画像認識の手法として、
CNN(Convolutional Neural Network)の仕組みと実装方法について説明しました。
字ずらを見ると何やら難しそうな印象を受けたかもしれませんが、順を追って中身を見ていくと意外と単純な手法でしたね。
次回は、
「第10回(最終回):リカレントニューラルネット(RNN)で翻訳AIを自作する」です。
お楽しみに!
参考書籍
今回記事内で使用したソースコードは「ゼロから作るDeeplearning」のものを改変して使用させていただきました。





