

こんにちは、えびかずきです。
今回は、ディープラーニングで画風変換のジェネレータを実装して、写真をゴッホ風に変換する方法について説明したいと思います。
ソースコード
ソースコードはGithubにてjupyter notebook形式(.ipynb)公開しています。
↓こちらからダウンロードしてご利用ください。
https://github.com/ebikazuki/tensorflow
開発環境
OS:MacOS Catalina 10.15.2
プロセッサ:2.6 GHz デュアルコアIntel Core i5
言語:Python3.5.4
開発ツール:jupyter notebook
使用ライブラリ:
・tensorflow 1.5.0(要install)
・pillow 5.0.0(tensorflowが内部で利用)(要install)
・numpy 1.17.4(要install)
・math(標準ライブラリ)
・os(標準ライブラリ)
・json(標準ライブラリ)
・pickle(標準ライブラリ)
画風変換の仕組み
autoencoder(オートエンコーダ)について
まず、画像変換をどのようにして実装するかについて説明したいと思います。
画像変換には、基本的に下図に示すautoencoder(オートエンコーダ)というものを使用します。これは情報量を圧縮するencoder(エンコーダ)とそれを復元するdecoder(デコーダ)から構成されるニューラルネットです。
autoencoderは、元々は情報量の圧縮によるデータ量削減を目的としたものですが、encoderの部分で特徴量のベクトルが抽出されるという点でさまざまな応用が可能です。
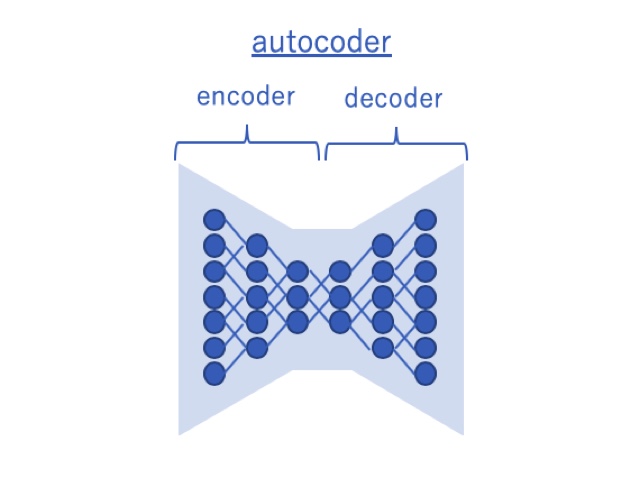
通常オートエンコーダは学習データと教師データを同一として、情報の圧縮→復元を学習しますが、今回は教師データにある工夫をすることで画風変換を実装します。
CAEによるGeneratorの実装
今回は画像を扱うため、autoencoderとしてCNN(convolutional neural network)を使用したCAE(CNN-autoencoder)を画像変換のGeneratorとして利用します。
・画風の教師データ
画風の教師データとしては、ゴッホの【糸杉のある麦畑,1889】を使用しました。
ゴッホの画風変換としては、有名な【星月夜】や【夜のカフェテラス】などがよく使われているようですが、それと同じことをしてもあまり面白くないので、今回はあえて少しマイナーな作品を使用してみました。

ではどうやって画風変換を実装するか順を追って説明します。
学習データとして写真の学習画像をインプットさせ、Generatorによって生成されたアウトプット画像を、さらに特徴量を抽出するためのニューラルネット(VGG16の一部を利用) へインプットとして導入し、特徴量のデータを得ます。
得られた特徴量が、スタイルの参考となる画像(今回はゴッホの絵)の画風(いわゆるスタイル)の特徴量と似ているか?という比較します。この特徴量が似ているということがすなわち画風が似ているということに直結します。
加えてさらに、元の画像の写真としての構造の特徴量と似ているか?という比較をします。この特徴量が似ていれば、写真自体の構成(ものの配置や色など)が似ているということになります。
上記2点の特徴量が期待通り合うように学習させます。
具体的にはそれぞれの差異を損失関数として定義してやり、多数の学習画像を使って最適化することでGeneratorを作成することができます。
簡単におさらいすると、学習の流れとしては以下のようになります。
① 学習画像をGenerator(CAE)で変換する
② ①のアウトプット、学習画像、画風画像の3つの特徴量抽出をする(VGG16)
③ 画像の構造は学習画像に近く、画風の特徴量は画風画像に近くなるように損失関数を定義してGeneratorの重みを調整する
④ 画風変換Generatorの完成!
※今回は使用した学習画像は約1000枚(224×224)。
※終了条件は10epoch。
※学習には約五時間程度かかりました。(マシンは開発環境に記載のとおり普通のMacbook-proです。)
※ソースコードの詳細はGithubから確認ください。
画風変換Generatorの評価
それでは実際に作成したGeneratorの性能を評価してみましょう!
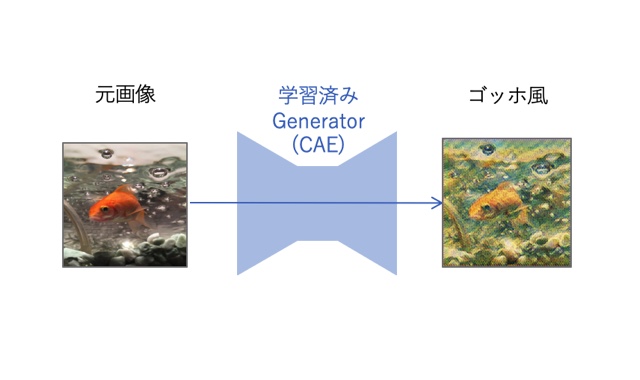
まずは、金魚の写真を変換してみました。

変換前-金魚 
変換後-金魚
全体的に画質が粗めで色味には曇りがありますが、ある程度いい感じに仕上がりました。
背景に金魚の赤が映えていて、泡もいい感じに表現されています。
まずまずの出来ではないでしょうか?
ちなみにこの金魚は、えびかずきが6年ほど前に屋台で掬って飼い始めた金魚ですが、1歳半ぐらいの時に病気にかかりお亡くなりになってしまいました。。。
遺影として天国の彼に捧げます。
お次は、太陽の塔です。

変換前-太陽の塔 
変換後-太陽の塔
雲がいい感じに表現されていると思います。
そもそも元の画像が美しいというのもありますが笑
次はバリ島の寺院です。

変換前-バリの寺院 
変換後-バリの寺院
色は少し曇ったようになってしまいましたが、寺院の造形が芸術的に表現されているように思います。
もしかすると今回のGeneratorは風景よりも建物の方が合っているかもしれません。
次は、台湾の九份の街並みです。

変換前-台湾の九份 
変換後-台湾の九份
変換すると赤の提灯が特徴的でノスタルジックな雰囲気がグッと増したように感じます。まあまあの出来です。
最後に水面を泳ぐ鳥です。
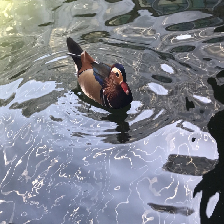
変換前-鳥 
変換後-鳥
水面の波が綺麗に表現されていますが、画像中心付近へ特異的にカラフルなノイズが入ってしまっています。
学習が少し不十分なのかもしれません
まとめ
今回は、CAE(Convolutional Autoencoder)を使った画風変換の実装について説明しました。
CAEによるGeneratorとVGG16による特徴量抽出を組み合わせて学習させることで写真をゴッホ風に変えられることを確認できました。
ただ、実際こういった多数の画像を扱うディープラーニングの学習にはGPUを使用する方が効率が良く、さらなる精度向上が見込めます。
しかしながら筆者えびかずきにGPUの持ち合わせがあるわけもなく、クラウドで使うのも面倒なので今回は自前のMac-PCで学習させました。
機会があればGPUを活用して、精度の高いGeneratorを作ってみたいと思います!
参考文献
今回の記事は、以下の書籍を参考にさせていただきました。





