

こんにちは、えびかずきです。
機械学習モデルの汎化性能評価のやり方についてまとめていきたいと思います。
こんな人におすすめ:
・学習済みモデルの評価方法についてPythonで学びたい
・機械学習の入門で「はじパタ」を読んでいるが難しいので解説して欲しい
機械学習をしっかり学びなおそうと思って、最近「はじめてのパターン認識」を読んでいます。
しかし残念ながらPythonでの実装例が無いので本書を読むだけでは、理論の理解に留まり実践的ではありません。
ということで今回は、はじパタ2章をPythonで実装しながら読み進めた記録を備忘録的に残しておこうと思いました。
開発環境
Python 3.7.3
scikit-learn 0.24.2
NumPy 1.20.2
IDE:jupyter Notebook
汎化性能評価の手法
今回はサンプルデータとして、sklearn.datasetsのmake_blobで生成したデータを使うことにします。
以下のようにして2クラス100サンプルのデータを生成します。
from sklearn.datasets import make_blobs
X, y = make_blobs(centers=2, random_state=4, n_samples=100, n_features=2)どんなデータセットかは過去記事を参照ください。
ホールドアウト法
それではまず、ホールドアウト法の実装例です。
ホールドアウト法はサンプルデータ全体を訓練データとテストデータに分けて、その二つの精度を見比べるという最も単純な方法です。
ホールドアウト法は計算負荷の小さいので、データが多い場合に使い勝手がよい評価方法です。
ただし分割の仕方次第では評価にばらつきがでる可能性が高く、データが少ない場合には信頼性が低くなってしまいます。
まず、データの分割は以下のように「train_test_split」を使って実施します。
from sklearn.model_selection import train_test_split
import numpy as np
# デフォルトはtest_size=0.25
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
では分類器モデルとしてSVMを採用した場合の、精度をみていきましょう。
以下のようにSVMモデルを訓練データで学習させた後、scoreメソッドで精度を評価します。
#SVM/ホールドアウト法
from sklearn.svm import SVC
model = SVC(C=1,gamma=1)
classifier = model.fit(X_train, y_train)
print("train score:",classifier.score(X_train, y_train))
print("test score:",classifier.score(X_test, y_test))
# OUTPUT:
# train score: 0.97
# test score: 0.96このケースでは、訓練データ、テストデータ共に精度は高く、良い学習モデルになっていることが確認できました。
ハイパーパラメータの最適化:
次に最適なハイパーパラメータを見積もるためのコードを紹介します。
以下のようにSVCのハイパーパラメータであるガンマをさまざまな値に変えて、精度を確認してみます。
#SVM opt./ホールドアウト法
from sklearn.svm import SVC
import pandas as pd
log_gamma = []
train_score = []
test_score = []
for i in range(-5, 3):
model = SVC(C=1, gamma=10**i)
classifier = model.fit(X_train, y_train)
log_gamma.append(i)
train_score.append(classifier.score(X_train, y_train))
test_score.append(classifier.score(X_test, y_test))
# seabornでグラフ化
import seaborn as sns; sns.set()
df = pd.DataFrame()
df["log_gamma"] = log_gamma
df["train_score"] = train_score
df["test_score"] = test_score
sns.lineplot(x="log_gamma",y="train_score",data=df);
sns.lineplot(x="log_gamma",y="test_score",data=df);スコアを図示した結果がこちらです。
青が訓練データの精度、オレンジはテストデータの精度を示しています。

訓練データはガンマが大きくなっても精度が高いですが、テストデータはガンマが大きくなりすぎると精度が下がっています。
これはガンマが大きいところではモデルが過学習をしてしまっているということを示しています。
結論として、ガンマは対数表示で、-2~0あたりに設定するのが良さそうです。
交差確認法
続いて交差確認法の実装例です。
交差確認法というのは、サンプルデータをN分割して、テストデータとするグループを変えながらN回訓練と精度評価を実施する方法です。
普通はこれで得られたN個の結果の平均値を採用します。
交差確認法のメリットは分割の仕方による精度振れを緩和できるという点が挙げられます。
要するに、ホールドアウト法で懸念点だった評価のばらつきを克服できる手法というわけです。
交差確認法は、cross_val_score関数を使って実装します。
引数のcvのところでデータをいくつのグループに分割するかを指定できます。
#SVM opt./交差確認法
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
import pandas as pd
X, y = make_blobs(centers=2, random_state=4, n_samples=100, n_features=2)
log_gamma = []
score = []
for i in range(-5, 3):
model = SVC(C=1, gamma=10**i)
scores = cross_val_score(model, X, y, cv = 3)
log_gamma.append(i)
score.append(np.mean(scores))
# seabornでグラフ化
import seaborn as sns; sns.set()
df = pd.DataFrame()
df["log_gamma"] = log_gamma
df["score"] = score
sns.lineplot(x="log_gamma",y="score",data=df);交差確認法でテストデータの精度を評価した結果がこちら。
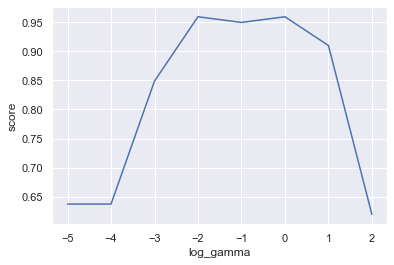
こちらでもやはり、ガンマは対数表示で-2~0あたりに設定するのが良さそうです。
一つ抜き法
続いて一つ抜き法の実装例です。
一つ抜き法というのは、テストデータは1つだけにして、訓練と精度評価をサンプルデータの総数分実行するという方法です。
これは言い換えると、交差確認法の分割数を究極的に大きくした評価手法とも言えます。
信頼性は高いですが、計算量が多くなってしまうので、特にサンプルデータ数が少ない時に推奨される手法です。
実装例はこちらです。
cross_val_score関数の引数にLeaveOneOut()を指定して実装します。
#SVM opt./一つ抜き法
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
import pandas as pd
from sklearn.model_selection import LeaveOneOut
X, y = make_blobs(centers=2, random_state=4, n_samples=100, n_features=2)
log_gamma = []
score = []
loo = LeaveOneOut()
for i in range(-5, 3):
model = SVC(C=1, gamma=10**i)
scores = cross_val_score(model, X, y, cv = loo)
log_gamma.append(i)
score.append(np.mean(scores))
# seabornでグラフ化
import seaborn as sns; sns.set()
df = pd.DataFrame()
df["log_gamma"] = log_gamma
df["score"] = score
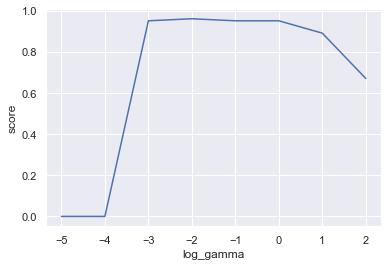
sns.lineplot(x="log_gamma",y="score",data=df);結果がこちら。
一つ抜き法だど、ガンマが対数表示で-3~0くらいにするのが良さそうだという結果です。
ブートストラップ法
ここでは、scikit-learnによるブートストラップ法の実装方法を紹介したいところですが、私が使っているscikit-learn 0.24.2では、対応する関数やメソッドがありません。
調べてみたところ、過去のバージョンではsklearn.cross_validation.Bootstrapという関数があったみたいですが、今は残念ながらなくなってしまっているようです。
ブートストラップ法というのは統計学的なテクニックでバイアスを見積もる方法ですが、おそらく汎化精度の向上を目的とした場合、あまり実用的ではないために外されてしまったのではないかと思います。
まとめ
今回は機械学習モデルの汎化性能評価のやり方についてまとめました。
機械学習の予測モデルはどれだけ学習データにフィットしていても、汎化性能が高くなければ意味がありません。
性能評価をしつつトライアンドエラーでよいモデルを構築していきましょう!





