

こんにちは、えびかずきです。
今回は機械学習や統計解析の事前処理として、データの標準化や無相関化を実施する方法について説明していきます。
こんな人におすすめ:
・データの標準化と無相関化についてPythonで学びたい
・機械学習の入門で「はじパタ」を読んでいるが難しいので解説して欲しい
開発環境
Python 3.7.3
scikit-learn 0.24.2
NumPy 1.20.2
Pandas 1.2.4
seaborn 0.11.1
使用するデータ:iris/sklearn.datsets
エディタ:jupyter Notebook
データの準備
今回はサンプルデータとして、はじパタで紹介されているものと同じ、アヤメのデータを使います。
Pythonの場合、scikit-learnのdetasetsに組み込まれいるので、そちらを使えます。
データは以下のようにして、ロードできます。
from sklearn.datasets import load_iris
iris = load_iris()このデータセットの中には、特徴量データとして、アヤメのがく(sepal)の長さと幅、そして花弁(petal)の長さと幅、の計4次元のデータが150セット入っています。
そしてターゲットデータとしてアヤメの品種である「setosa:0」「versicolor:1」「virginica:2」がそれぞれ50個づつ割り当てられています。

それぞれの品種については、以下の記事が参考になりました。
データ可視化
ロードしたアヤメのデータを可視化してみます。
まずデータを扱いやすくするために、Pandasのデータフレームに変換しておきます。
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df.loc[df['target'] == 0, 'target'] = "setosa"
df.loc[df['target'] == 1, 'target'] = "versicolor"
df.loc[df['target'] == 2, 'target'] = "virginica"
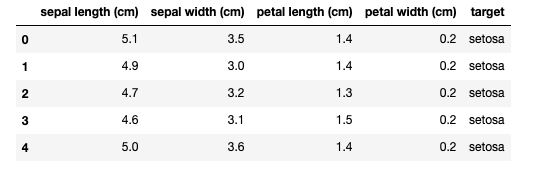
df.head()データフレームの最初の部分を表示するとこんな感じです。
では、seabornを使ってデータを可視化してみましょう。
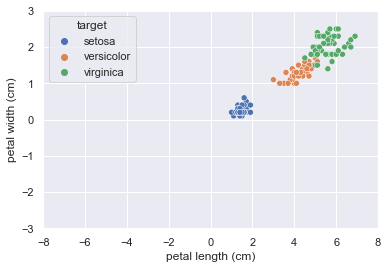
ここでは、はじパタで紹介されているグラフと同様に、花弁(petal)の長さと幅の2次元の情報に絞ってデータを表示します。
import seaborn as sns; sns.set()
sns.scatterplot(data=df, x='petal length (cm)', y='petal width (cm)', hue='target')
import matplotlib.pyplot as plt
plt.xlim(-8, 8)
plt.ylim(-3, 3);それぞれの品種が割と綺麗に分かれていますね。
標準化
では本題に入っていきましょう。
まず標準化ですが、Pythonで実装する場合はsklearn.preprocessingのStandardScalerを使って以下のようにします。
# まず花弁の長さと幅のデータのみを抜き出す
X = iris.data[:, [2, 3]]
y = iris.targetfrom sklearn.preprocessing import StandardScaler
# StandardScalerで標準化
scaler = StandardScaler()
X_sc = scaler.fit_transform(X)
df['petal length (cm)'] = X_sc[:,0]
df['petal width (cm)'] = X_sc[:,1]
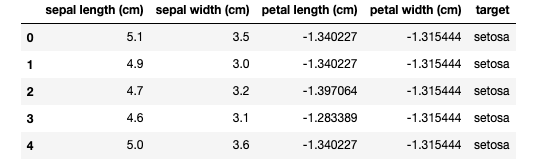
df.head()データフレームの最初の部分を表示したものが以下です。
花弁の長さ(petal length)と花弁の幅(petal width)が標準化されているのがわかりますね。
続いて、標準化したデータを可視化してみます。
import seaborn as sns; sns.set()
import matplotlib.pyplot as plt
sns.scatterplot(data=df, x='petal length (cm)', y='petal width (cm)', hue='target')
plt.xlim(-8, 8)
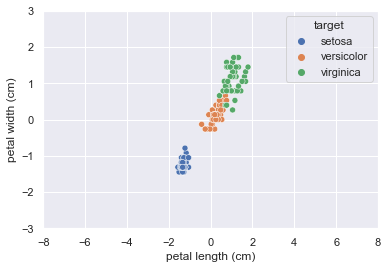
plt.ylim(-3, 3);標準化することで、データの中心(すなわち平均値)が、グラフの中心にシフトしていて、分散は1に整えられています。
こうすることでデータが扱いやすくなりました。
無相関化
続いて無相関化です。
無相関化はsklearn.decompositionモジュール の PCAクラスを使って実装できます。
無相関化はすなわち主成分分析(PCA;principal component analysis)のデータ処理と同一です。
手順は以下のとおり。
import numpy as np
from sklearn.decomposition import PCA
pca = PCA()
X_uncorr = pca.fit_transform(X_sc)
df['1stPC'] = X_uncorr[:,0]
df['2ndPC'] = X_uncorr[:,1]
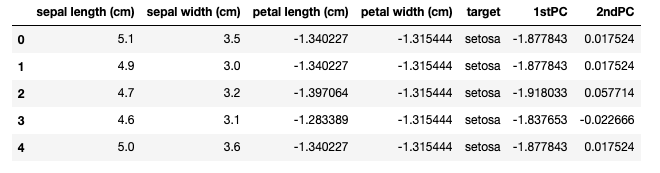
df.head()データフレームの上部を表示したものが下図です。
無相関化によって新たに作られた特徴量の次元(1stPC,2ndPC)が追加されていますね。
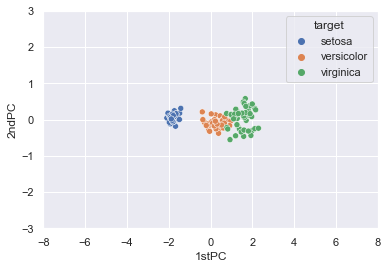
では結果を図示してみましょう。
import seaborn as sns; sns.set()
import matplotlib.pyplot as plt
sns.scatterplot(data=df, x='1stPC', y='2ndPC', hue='target')
plt.xlim(-8, 8)
plt.ylim(-3, 3);データが回転して相関係数=0の新しい軸ができていますね。
まとめ
今回は機械学習や統計解析向けに、データの標準化と無相関化をする方法について説明しました。
標準化は割と理解しやすいですが、無相関化について線形代数と統計学の知識がないと少し理解するのが難しいかもしれません。
しかしやっていることは単純で、相関係数が0になるように回転しているだけです。
数式を追うと難しいですが、感覚的には理解しやすい筈。
理論を学ぶ時は、まずは感覚を掴んで、その後数式を追うようにすると理解が進むのが早いのでおすすめです。
今回は以上。また次の記事でお会いしましょう!
参考
記事作成にあたって、以下の情報が参考になりました。
参考URL
[機械学習] iris データセットを用いて scikit-learn の様々な分類アルゴリズムを試してみた





